Main Page

IACL Group Photo from the Proceedings of SPIE Medical Imaging (SPIE-MI 2024), San Diego, CA, February 18–22, 2024.

Zhangxing Bian presenting his award winning paper "Is Registering Raw Tagged-MR Enough for Strain Estimation in the Era of Deep Learning?" at the Proceedings of SPIE Medical Imaging (SPIE-MI 2024), San Diego, CA, February 18–22, 2024.
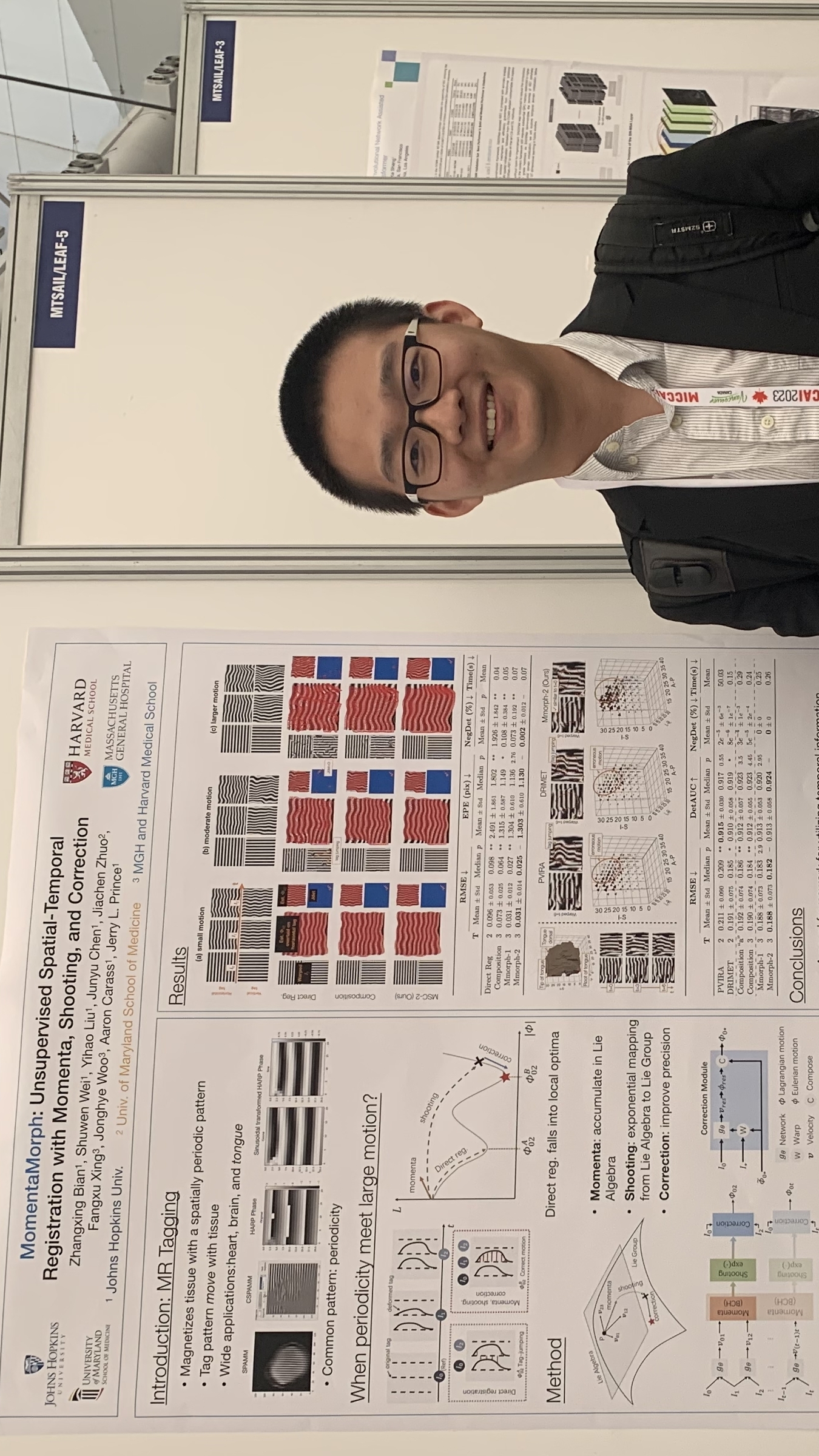
Zhangxing Bian presenting "MomentaMorph: Unsupervised Spatial-Temporal Registration with Momenta, Shooting, and Correction" at the MICCAI Workshop on Time-Series Data Analytics and Learning (MTSAIL 2023) in conjunction with the 26th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2023), Vancouver, Canada, October 8–12, 2023.

IACL Lab members at CMSC 2023 in Aurora, Colorado.

Dr. Muhan Shao being hooded by Prof. Jerry L. Prince.

Allen Hong giving a presentation capping off his REU Summer in IACL working with Dr. Ahmed Alshareef.

Lab members Lianrui Zuo and Yihao Liu with Dr. Yufan He after his graduation in May 2022.

Newly minted PhDs Drs. Blake Dewey and Yufan He flank Prof. J.L. Prince.

IACL lab members at SPIE-MI 2022.
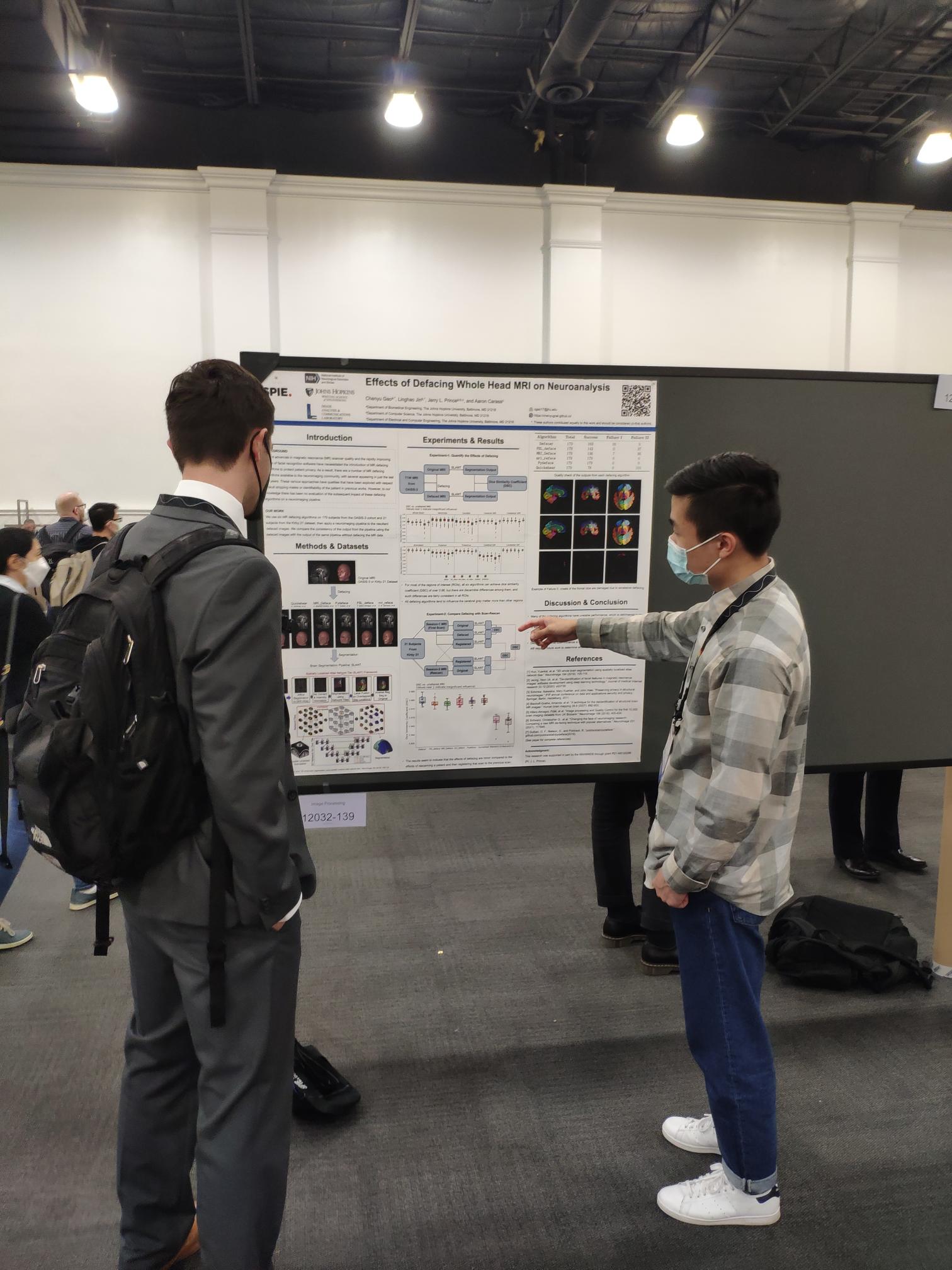
Chenyu Gao presenting his poster about MR defacing at SPIE-MI 2022.

Yihao Liu presenting a poster at SPIE-MI 2020.

Shuo Han presenting a poster at SPIE-MI 2020.

Yufan He wins a MICCAI Young Scientist Award at MICCAI 2019.

Prof. Jerry L. Prince congratulating Jeffrey Glaister on his successful defense in October 2019.
Yihao Liu presenting a poster at ISBI 2019.
Recent News Items
2024
March

NeuroImage Special Issue on Advances in Harmonization Techniques for Magnetic Resonance Imaging is open for submissions through September 1, 2024. The guest editors are:
- Aaron Carass, Johns Hopkins University
- Lianrui Zuo, Vanderbilt University
- Yihao Liu, Johns Hopkins University
- Jerry Prince, Johns Hopkins University
- Neda Jahanshad, University of Southern California
We welcome submissions of original research articles and comprehensive review papers focusing on, but not limited to, the following topics:
- Advanced approaches for MRI harmonization, which may include:
- Hybrid methods that combine different approaches
- Image synthesis methods
- Statistical methods
- Detailed evaluations of existing harmonization approaches in various neuroimage analysis tasks. Exploring strengths, limitations, and potential pitfalls of the existing methods.
- In-depth investigations of the applicability and effectiveness of harmonization methods across different MRI modalities, including:
- Structural MRI
- Diffusion MRI, such as diffusion tensor imagimg (DTI), high angular resolution diffusion imaging (HARDI), and diffusion kurtosis imaging (DKI)
- Functional MR
February

- Congratulations to Zhangxing Bian on winning a Best Paper Award at the Proceedings of SPIE Medical Imaging (SPIE-MI 2024), San Diego, CA, February 18–22, 2024.
- IACL papers at the Proceedings of SPIE Medical Imaging (SPIE-MI 2024), San Diego, CA, February 18–22, 2024.
- Zhangxing Bian presented "Is Registering Raw Tagged-MR Enough for Strain Estimation in the Era of Deep Learning?".
- Savannah P. Hays presented "Revisiting registration-based synthesis: A focus on unsupervised MR image synthesis".
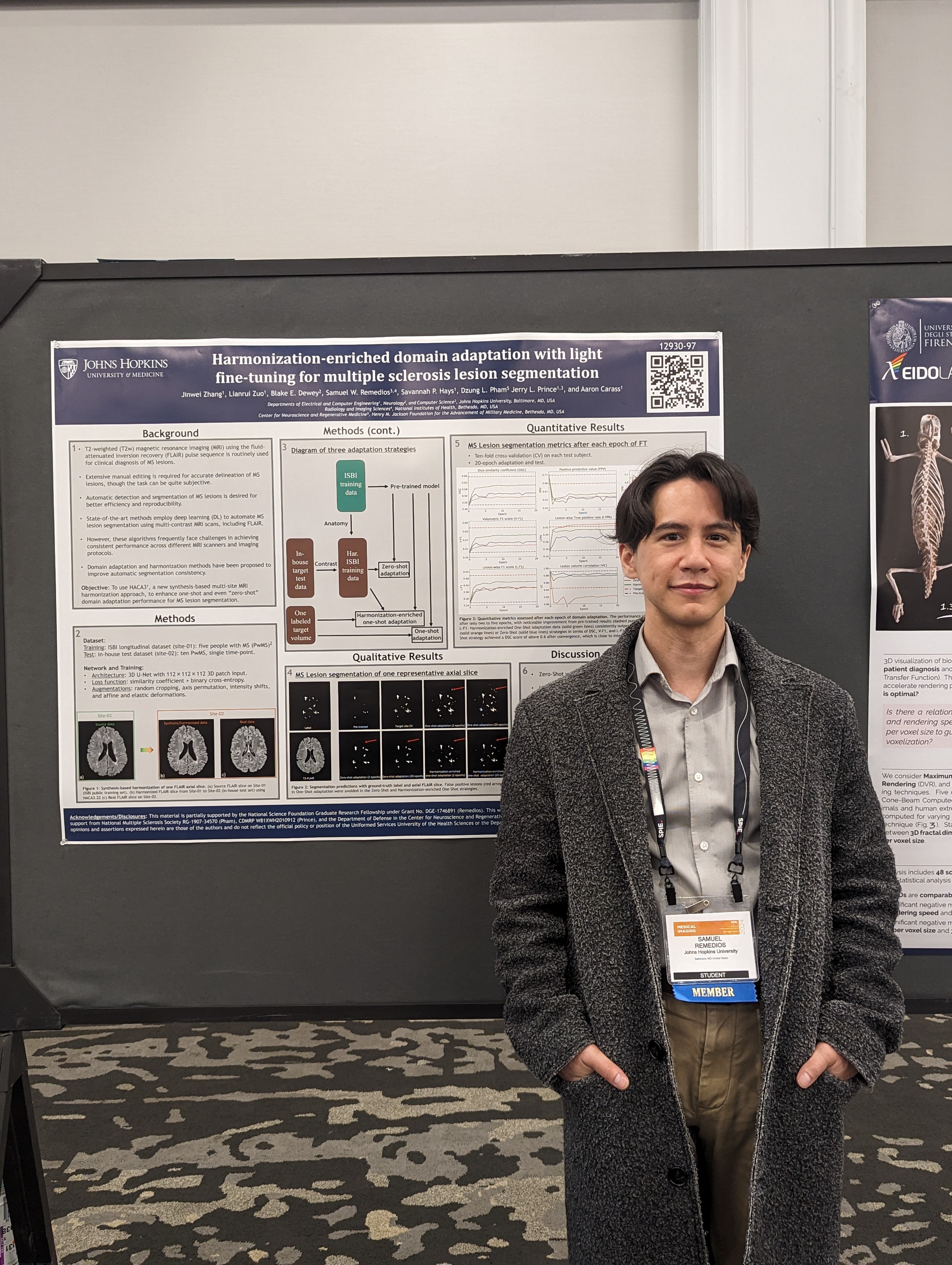
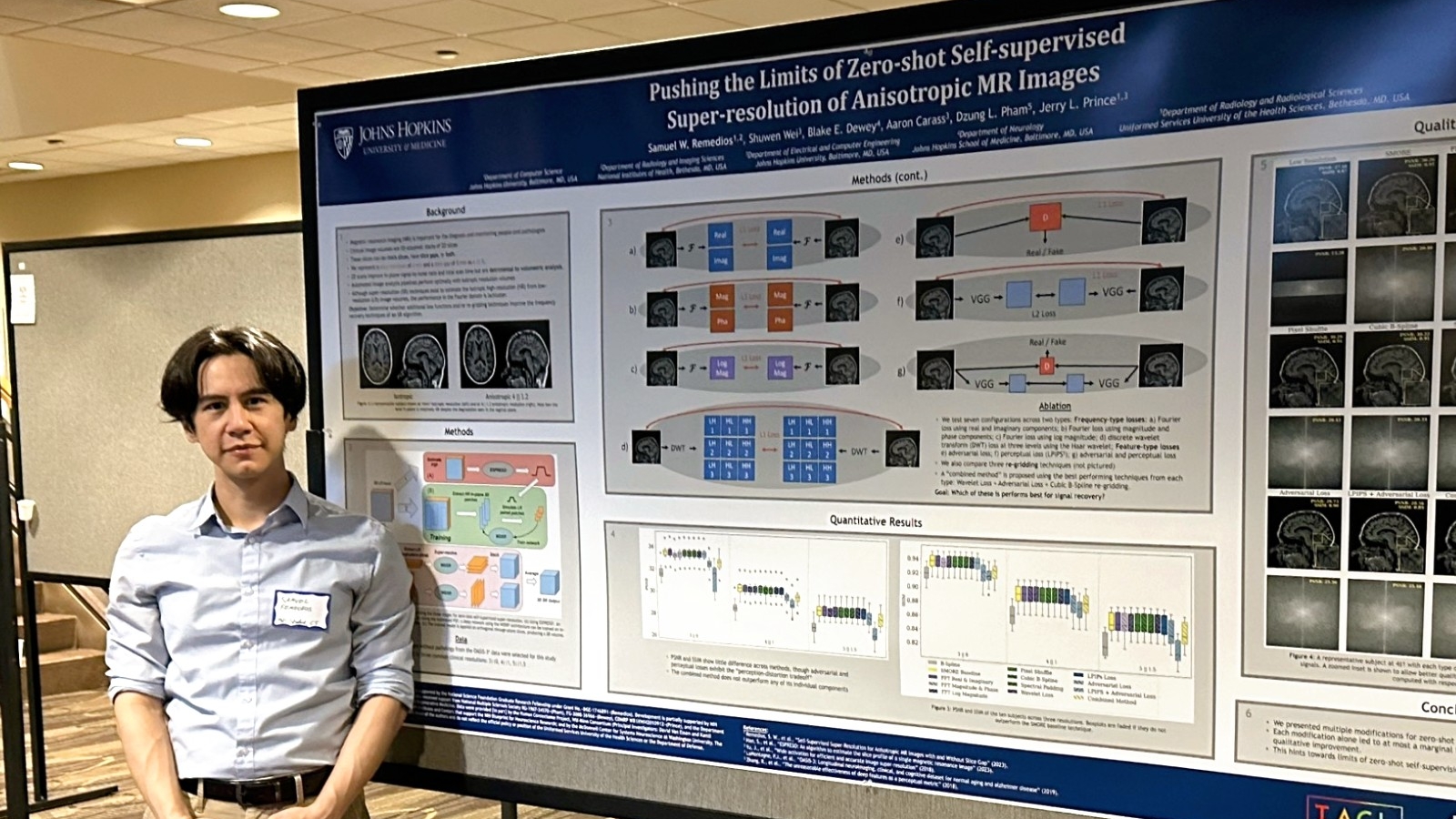
- Samuel Remedios presented "Pushing the limits of zero-shot self-supervised super-resolution of anisotropic MR Images" and "Harmonization-enriched domain adaptation with light fine-tuning for multiple sclerosis lesion segmentation".
- Dr. Yihao Liu presented "Deep learning-based segmentation of hydrocephalus brain ventricle from ultrasound".
- Zejun Wu presented "AniRes2D: Anisotropic residual-enhanced diffusion for 2D MR super-resolution".
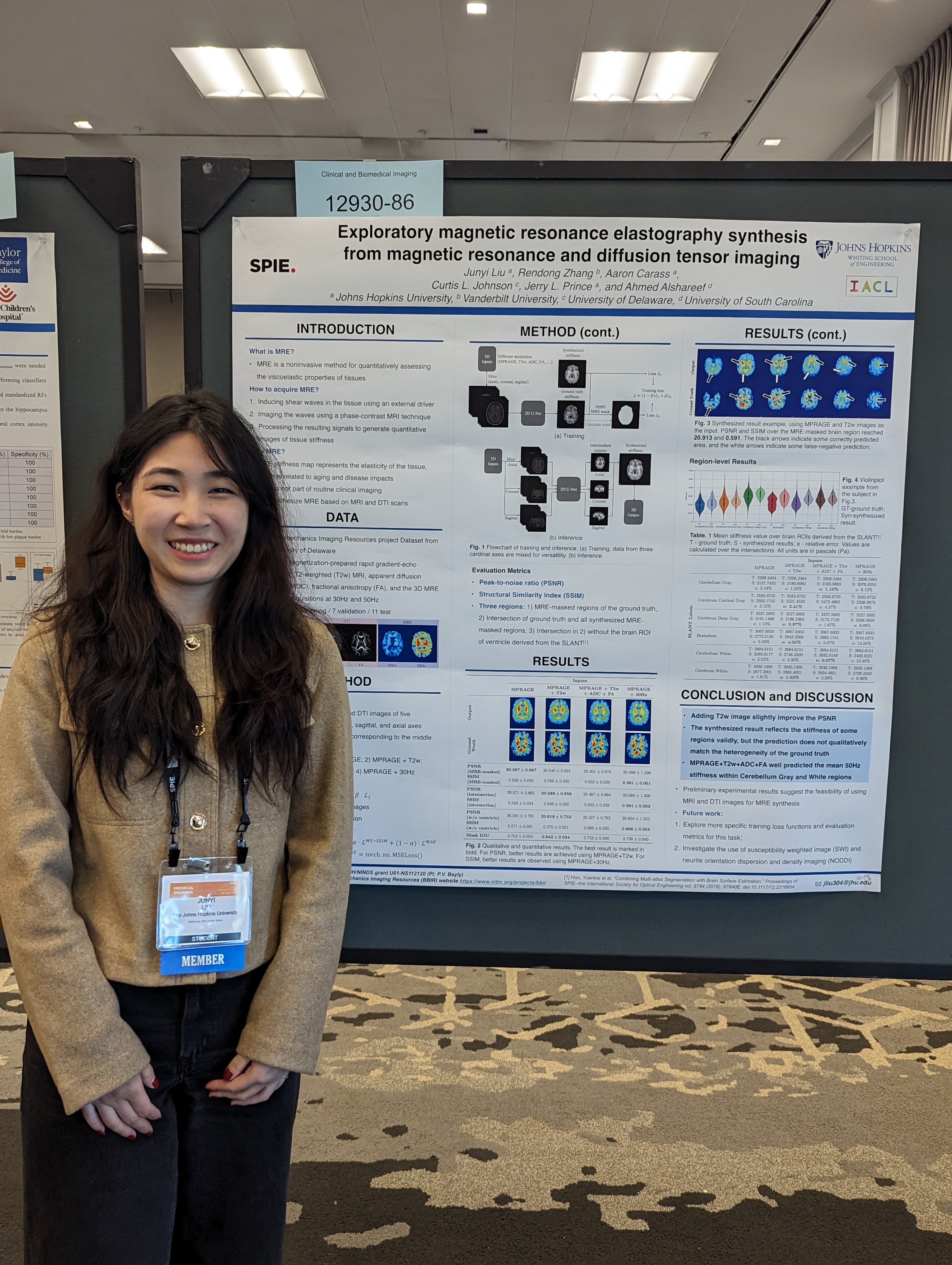
- Junyi Liu "Exploratory magnetic resonance elastography synthesis from magnetic resonance and diffusion tensor imaging".
- Other accepted papers at SPIE-MI 2024 coming from collaborations with IACL.
- Xiaofeng Liu from Massachusetts General Hospital, presented "Speech motion anomaly detection via cross-modal translation of 4D motion fields from tagged MRI".
| IACL at SPIE-MI 2024 | ||||

|
| |||
| Dr. Yihao Liu presenting Yuli Wang's work titled "Deep learning-based segmentation of hydrocephalus brain ventricle from ultrasound". | Zhangxing Bian presenting "Is Registering Raw Tagged-MR Enough for Strain Estimation in the Era of Deep Learning?". | |||

|

| |||
| Savannah P. Hays and Dr. Yihao Liu saying "Ayyy". | Samuel W. Remedios and Savannah P. Hays showing some SPIE pride. | |||

|
| |||
| IACL Lab members (new and old) at SPIE-MI 2024. | Samuel W. Remedios presenting "Harmonization-enriched domain adaptation with light fine-tuning for multiple sclerosis lesion segmentation". | |||
|
||||
| Junyi Liu presenting her poster titled "Exploratory magnetic resonance elastography synthesis from magnetic resonance and diffusion tensor imaging". | ||||
| IACL at the Johns Hopkins School of Medicine and Whiting School of Engineering Research Retreat 2024 | ||||||
|

| |||||

|

| |||||
January
- Yihao Liu successfully defends his thesis titled "Methods for Automated Analysis of OCT and OCTA Images".
- Lianrui Zuo successfully defends his thesis titled "Unsupervised structural MRI harmonization by learning disentangled representations".
2023
November

- "Deep Learning for Medical Image Analysis" 2nd edition is available for pre-order before its release in December 2023. It features two chapters from IACL Lab Members.
- Lianrui Zuo is the lead author of Chapter 5 titled "An overview of disentangled representation learning for MR images". (doi)
- Yihao Liu is the lead author of Chapter 16 titled "OCTA Segmentation with limited training data using disentangled representation learning". (doi)
- The book is available direct from Elsevier, as well as from Amazon.
- Chenyu Gao at Vanderbilt has co-authored a paper with us titled "Reproducibility evaluation of the effects of MRI defacing on brain segmentation" that has appeared in the Journal of Medical Imaging. (doi)

- IACL group members attending the Americas Committee for Treatment and Research in Multiple Sclerosis (ACTRIMS) Young Scientist Summit in Clinical Neuroimmunology from October 30 thru November 2 in Scottsdale, Arizona, include:
October
- IACL papers at the 26th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2023), Vancouver, Canada, October 8–12, 2023.
- Dr. Shuwen Wei presented "Recurrent Self Fusion: Iterative Denoising for Consistent Retinal OCT Segmentation", 10th Ophthalmic Medical Image Analysis Workshop (OMIA 2023) in conjunction with the 26th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2023), Vancouver, Canada, October 8–12, 2023. (doi)

- Samuel W. Remedios presented "Self-Supervised Super-Resolution for Slice Gap MRI", Simulation and Synthesis in Medical Imaging (SASHIMI 2023) in conjunction with the 26th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2023), Vancouver, Canada, October 8–12, 2023. (doi)
- Zhangxing Bian presented "MomentaMorph: Unsupervised Spatial-Temporal Registration with Momenta, Shooting, and Correction", MICCAI Workshop on Time-Series Data Analytics and Learning (MTSAIL 2023) in conjunction with the 26th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2023), Vancouver, Canada, October 8–12, 2023.

- Dr. Shuwen Wei presented "Recurrent Self Fusion: Iterative Denoising for Consistent Retinal OCT Segmentation", 10th Ophthalmic Medical Image Analysis Workshop (OMIA 2023) in conjunction with the 26th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2023), Vancouver, Canada, October 8–12, 2023. (doi)
- HACA3 Code for MR Harmonization is available. The method is described in:
- L. Zuo, Y. Liu, Y. Xue, B.E. Dewey, S.W. Remedios, S.P. Hays, M. Bilgel, E.M. Mowry, S.D. Newsome, P.A. Calabresi, S.M. Resnick, J.L. Prince, and A. Carass, "HACA3: A unified approach for multi-site MR image harmonization", Computerized Medical Imaging and Graphics, 109:102285, 2023. (doi)
- L. Zuo, Y. Liu, Y. Xue, B.E. Dewey, S.W. Remedios, S.P. Hays, M. Bilgel, E.M. Mowry, S.D. Newsome, P.A. Calabresi, S.M. Resnick, J.L. Prince, and A. Carass, "HACA3: A unified approach for multi-site MR image harmonization", Computerized Medical Imaging and Graphics, 109:102285, 2023. (doi)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}